Archived
Performance comparison between Ice and omniORB

I did some performance comparison between Ice and omniORB.
I just send 100 x 10 000 remote calls, and do the average of the time it takes (so, it is the average time it takes (on 100 iterations) to send 10 000 remote calls).
I was surprised when I obtained these results :
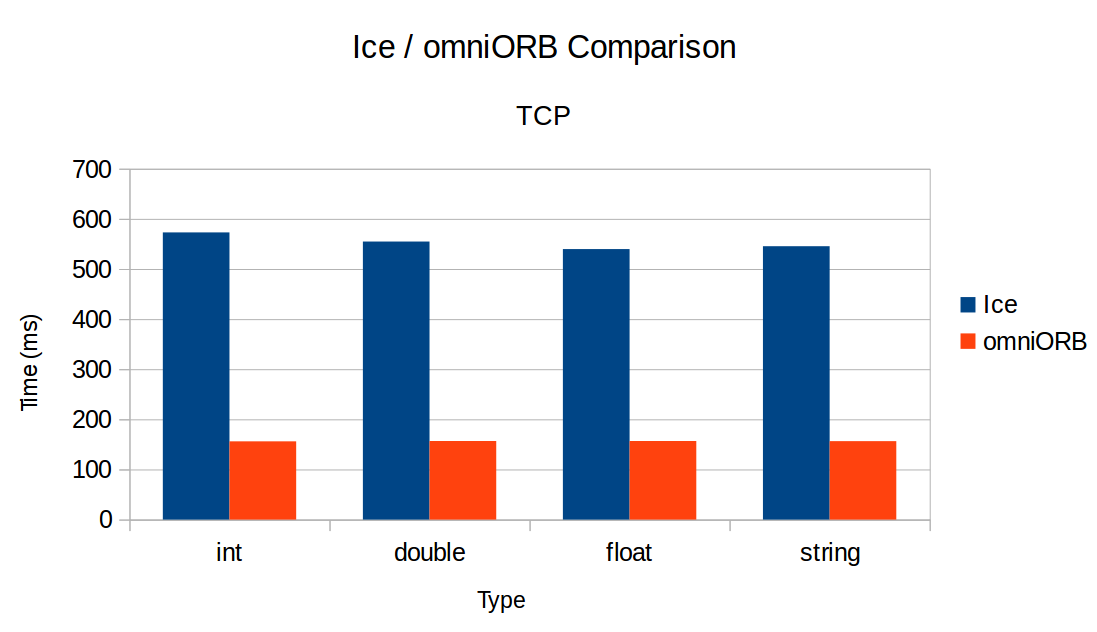
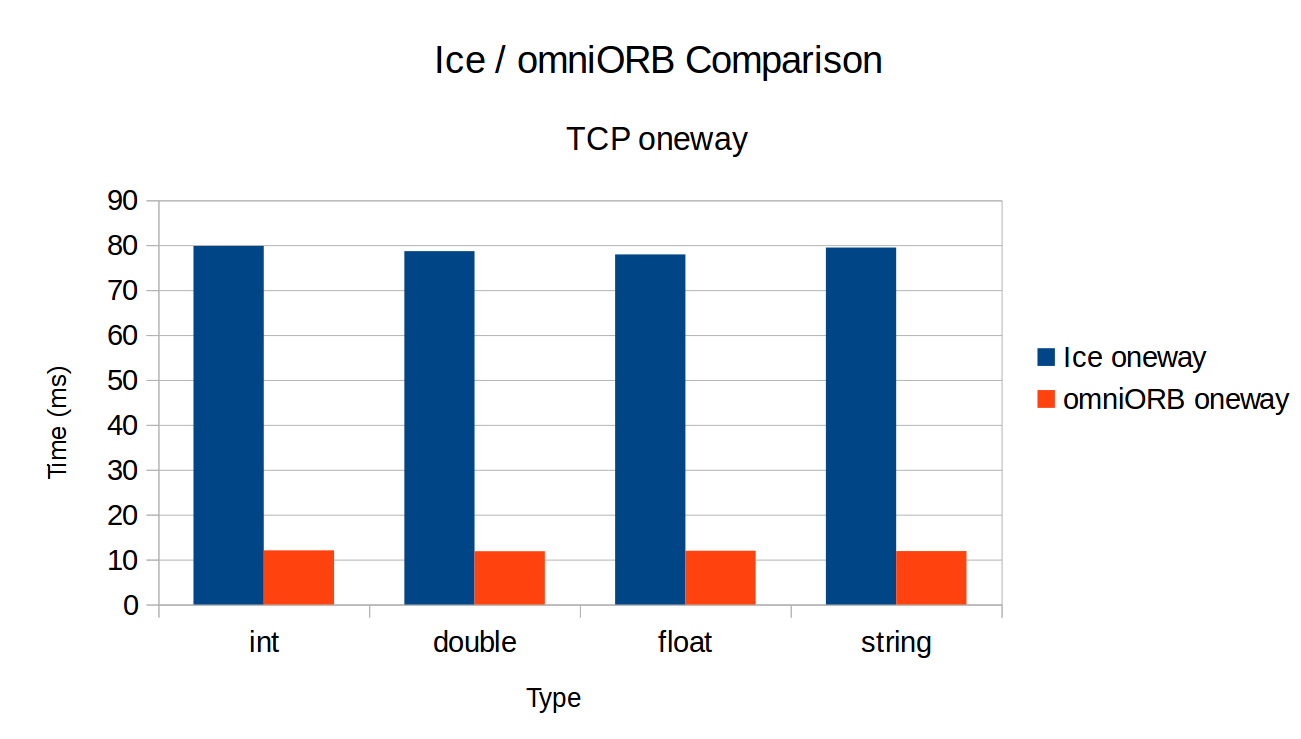
How could you explain this difference ? Is my test not good ? Or is Ice slower than omniORB ?
Regards.
Comments
-
Hi Clement,
Welcome to our forums!
I am guessing you are comparing the performance of operations with just one int, double, float or string parameter, something like:
void opInt(int x); void opDouble(double x);
And you're getting about the same result regardless of the type, which not surprising since the marshaling/unmarshaling of this one parameter is negligible compared to overhead associated with sending and receiving the request. I would actually anticipate less variations that you have. Here you are measuring the latency of Ice and OmniORB requests, presumably in C++ for calls on the same computer.
We provide a latency demo that you should use to check your Ice numbers. Make sure to build it with optimization ("Release" on Windows). On my Windows 10 PC with VS 2015 x64, I get:
pinging server 100000 times (this may take a while) time for 100000 pings: 2189.56ms time per ping: 0.021895ms
So 10,000 pings (Ice 2-ways requests) would tale 219 ms on my Windows 10 PC. Your results are in the 550ms range; maybe your system is slower?
With Ice, a client and server running on the same machine communicate over TCP typically using the loopback (127.0.0.1).
OmniOrb provides a Unix-domain socket transport (for Unix-like systems), which could provide better latency than loopback for a client and server on the same system. Is this what you used for OmniOrb? Can you post the source code for your benchmark?
All the best,
Bernard0 -
Hello. Thank you for the quick answer.
I am guessing you are comparing the performance of operations with just one int, double, float or string parameter
presumably in C++ for calls on the same computer
Yes, exactly.
I did not precise it, but I'm using Ubuntu 14.04LTS.The latency demo gives these (surprising?) results :
pinging server 100000 times (this may take a while) time for 100000 pings: 8316.31ms time per ping: 0.083163ms
I just used the "make" command to compile.
So 10 000 pings would take 832ms... but I obtain approximately 500 ms. I don't understand why.Attached is the source code for my little benchmark. Just use
cmake . -G"Unix Makefiles"thenmake.For omniORB, I did not use Unix-domain socket transport but TCP. With the Unix-domain socket transport, omniORB is a little bit faster :
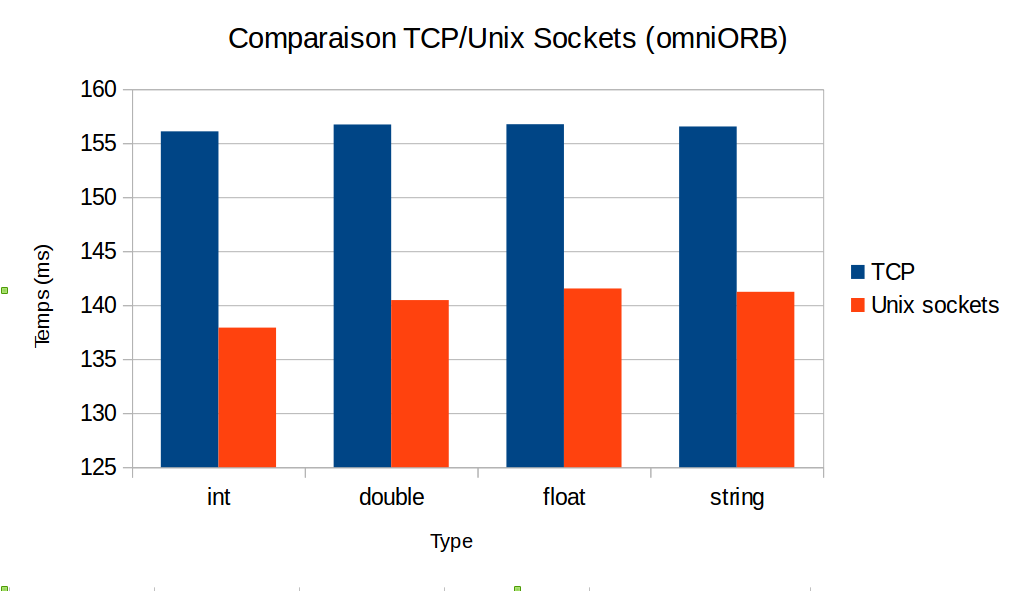
Any idea ?
Regards.
Clément.0 -
Hi,
You should make sure to build the demo with optimization turned on. You can use
make OPTIMIZE=yesto build it with optimization.Did you build Ice yourself or did you get it from our Ubuntu 14.04 repository? If you built it yourself, you must also make sure it is built with optimization turned on (either set
OPTIMIZE=yesincpp/config/Make.rulesor provide it on the command line as shown above).Also, your test prints out some text on the standard output for each call (with
std::cout), I would remove these as it can significantly affect performances (were you doing the same for your omniORB test?)Let us know if this still doesn't help!
Cheers,
Benoit.0 -
Hi,
Sorry I forgot to build the demo with optimization.
When optimization is turned on, the results are better : I have values between 4000ms and 7000ms, but it seems to be very unstable. For example, here are some values measured consecutively :- 5145.95
- 5344.55
- 5849.41
- 5814.48
- 6067.18
- 6015.95
- 4202.84
- 4473.65
- 6818.4
- 5595.5
Why this instability ?
I built Ice myself (because the computer on which I do the tests doesn't have an internet connexion) but without optimization. So I have re-built it with optimization, and the results seem to be better : the average is around 400ms now (it was around 550ms before) for "normal" invocation. However, like I said before, the test is very unstable : sometimes it's around 350ms, and sometimes it's around 450ms.
Moreover, the results with oneway invocation are... worse : it was around 80ms before whereas it's around 120ms now.And yes, the test is the same on Ice and omniORB (the code is the same, except for the ORB/communicator initialization etc...), so there are std::cout on both.
To be sure, I have removed these std::cout of my code and the results are still the same.
Thank you for the time you take.
0 -
Hi,
It's hard to tell why there's so much variation between different runs. Could it be because of other processes running on your machine? You could try to modify the latency test to increase the number of iterations and see if you get more stable results when you let the test run longer.
Are the result more stable with your performance test? Are Ice performances closer to omniORB now that you have everything compiled with optimization?
Cheers,
Benoit.0 -
Hi,
Could it be because of other processes running on your machine
No I don't think so. I use the
clock()function from#include<ctime>.You could try to modify the latency test to increase the number of iterations and see if you get more stable results when you let the test run longer.
Yes I'll try this.
The result are not more stable with my performance test so I think the problem comes from my computer.
Are Ice performances closer to omniORB now that you have everything compiled with optimization?
Yes, but omniORB stays faster.
I think that choosing between omniORB and Ice is choosing between speed and ease of use, don't you think ?
Thank you.
Regards,
Clément.0 -
Hi Clément,
How faster is omniORB compared to Ice?
Regarding choosing between speed vs ease of use, it's in general not that simple
 . Depending on what you intend to do with it, there are few more criteria to consider when choosing a middleware technology, few of them:
. Depending on what you intend to do with it, there are few more criteria to consider when choosing a middleware technology, few of them:- latency, throughput and scalability (can it handle tens of thousand concurrent connections?)
- supported language mappings
- language features (support for asynchronous model with AMI, AMD)
- encoding features (support for optional parameters, optional data members, slicing)
- protocol features (support for two-way, one-way, batching, compression, bi-dir connections)
- threading models (thread pool vs thread per connection, ...)
- ease of use, technical support, documentation, ...
While omniORB might be slightly faster for a basic latency test, a distributed application is rarely that simple and this small performance difference is in general no longer noticeable when making invocations over a real network and when the server actually has to do some processing.
Cheers,
Benoit.0 -
While omniORB might be slightly faster for a basic latency test, a distributed application is rarely that simple and this small performance difference is in general no longer noticeable when making invocations over a real network and when the server actually has to do some processing.
Yes, I totally agree.
I don't denigrate Ice. It is just a fact.When I said "ease of use", I actually spoke about every thing you have just mentioned. It is surely because of my poor english
 .
.Indeed, a lot of things are better with Ice (documentation, language features, threading models, ease of use...) without forgetting this super technical support
.EDIT : There was an error in my code : I did not clear the vector after each
forloop. So the values were false.
However, after correction, the values are similar.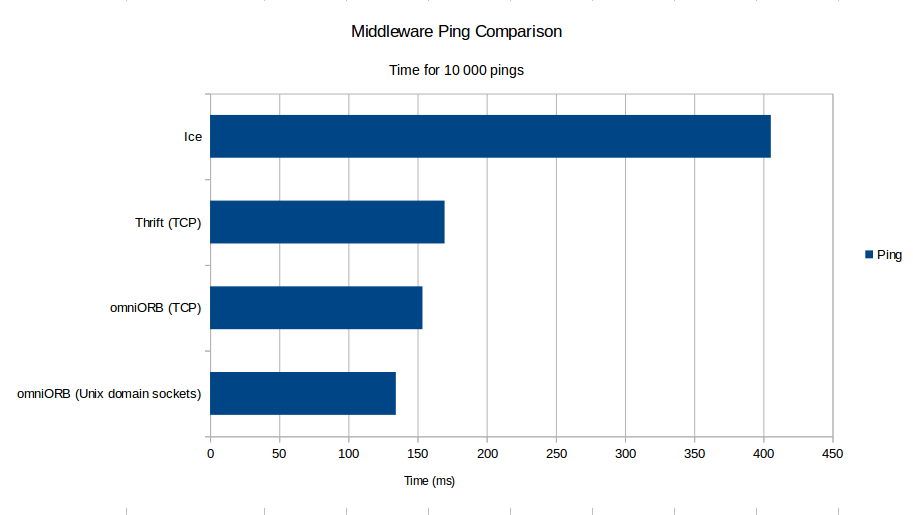
(I have added Apache Thrift in my test).
0 -
Hi,
I don't understand why you get such bad results for Ice. On which platform do you run your tests?
On OS X, I'm getting the following (time per call):
- omniORB (server w/ TPC - client w/ blocking): 34.9µs
- ominORB (server w/ TP - client w/ blocking): 36.5µs
- ominORB(server w/ TP - client w/o blocking): 38µs
- Ice 3.6.3: 55µs
So we're about 40% slower but clearly not more than twice as slow as omniORB as shown in your tests.
This is with the Ice latency demo and a port of the demo to ominORB (ping operation with no parameters). Can you post the code for both your Ice and omniORB test case? I can give it a try to see if I can reproduce the issue.
Cheers,
Benoit.0 -
Hi,
I don't understand either
On which platform do you run your tests?
I run my tests on a 64-bit Ubuntu 14.04LTS, Intel Xeon CPU @ 2.66GHz x 8, 7.8GiB of memory and 2.0TB on disk.
Can you post the code for both your Ice and omniORB test case?
Attached is the source code.
All in the same directory (it is not very clean, I am a beginner in CMake) :cmake . -G"Unix Makefiles"
Don't forget to set correctly the OMNI_DIR variable (it is your install directory of omniORB).makeThank you Benoit.
Regards,
Clément.0 -
Hi Clément,
So I finally ran your test on my macOS platform and I get similar results as yours except for oneway where Ice is actually faster than omniORB. If I change the timing primitive from
clock()togettimeofday(), I get similar results as the results I was observing with the latency test where Ice is bit slower than omniORB (around 40%).I believe this is caused by the threading models which are different between omniORB and Ice.
With Ice, the thread making the client invocation blocks on a condition variable waiting for the Ice client thread pool to send a notification when the reply is received. This enables the multiplexing of the client requests over the network connection and also allows dispatching the replies on AMI callbacks (from Ice client threads).
We could make Ice faster in the scenario of the performance test at the expense of added complexity in our sources and additional configuration. However, I doubt there's a realistic use case where such performance differences matter. As soon as you switch from the loopback interface to a physical network, as soon as you actually perform some processing in your servants, you will like observe a negligible performance difference.
Cheers,
Benoit.0 -
Hi,
except for oneway where Ice is actually faster than omniORB
That is really surprising. For me : Ice => 11,78 µs per call / omniORB => 1,17 µs per call
With Ice, the thread making the client invocation blocks on a condition variable waiting for the Ice client thread pool to send a notification when the reply is received.
I believe it is the same for omniORB. From here : "On the client side of a connection, the thread that invokes on a proxy object drives the GIOP protocol directly and blocks on the connection to receive the reply."
The default server side behaviour is "Thread per connection" mode, but trying with the thread pool mode gives the same result.Indeed, this speed difference is not a really big problem. The test I did was done for information on Ubuntu, but I will do other test on an embedded system (maybe with Yocto), and I will try to remember to show you the result.
Thank you very much.
0 -
Hi,
On my system (OS X), for oneway, I'm getting 49.9ms for Ice and 65.62ms for omniORB (average for 10000 calls).
Note that the "blocking" client threading model used by omniORB by default is quite limited since it basically allows only a single call per connection. The default server side thread per connection model also has the disadvantage of consuming lots of resources when there's a large number of clients...
It would be interesting to see a performance/scalability comparison when the client performs invocations from multiple threads or when the server dispatches requests from multiple threads. Comparing AMI/AMD performances would also be interesting since the asynchronous programming model is also used quite often with distributed applications.
Cheers,
Benoit.0 -
Hi,
Thank you for the explanation, I did not have understood the difference between the threading models.
0 -
Hi,
Finally, I'm not sure to have understood the difference between the threading models.
On the omniORB documentation, we can see : (here)"If two (or more) threads in a multi-threaded client attempt to contact the same address space simultaneously, there are two different ways to proceed.
The default way is to open another network connection to the server. This means that neither the client or server ORB has to perform any multiplexing on the network connections—multiplexing is performed by the operating system, which has to deal with multiplexing anyway.
The second possibility is for the client to multiplex the concurrent requests on a single network connection. This conserves operating system resources (network connections), but means that both the client and server have to deal with multiplexing issues themselves."
So, the multiplexing of the client requests over the network connection is possible too, isn't it ?
If it is, when I launch my benchmark, "setting the oneCallPerConnection parameter to zero", I get the exact same result.Thanks.
0